At 9:02am, a legal operations lead updates a clause in your master contract template. Compliance signed off. The new wording goes live.
At 9:14am, a sales rep asks the AI assistant a question that touches the clause. The assistant answers using the old wording. Confidently, accurately, professionally, because the cache still has it.
At 1:48pm, a deal closes on terms the company replaced four hours ago.
That afternoon, someone in your platform Slack types: "why didn't the AI know?" The answer that nobody likes giving: it knew. It just answered from cache. The cache won't refresh until its 24-hour timer rolls over at 9am tomorrow.
This is not a hypothetical. Some version of this scenario is the single most common reason enterprise AI rollouts get pulled out of regulated workloads. It is also one of the most preventable.
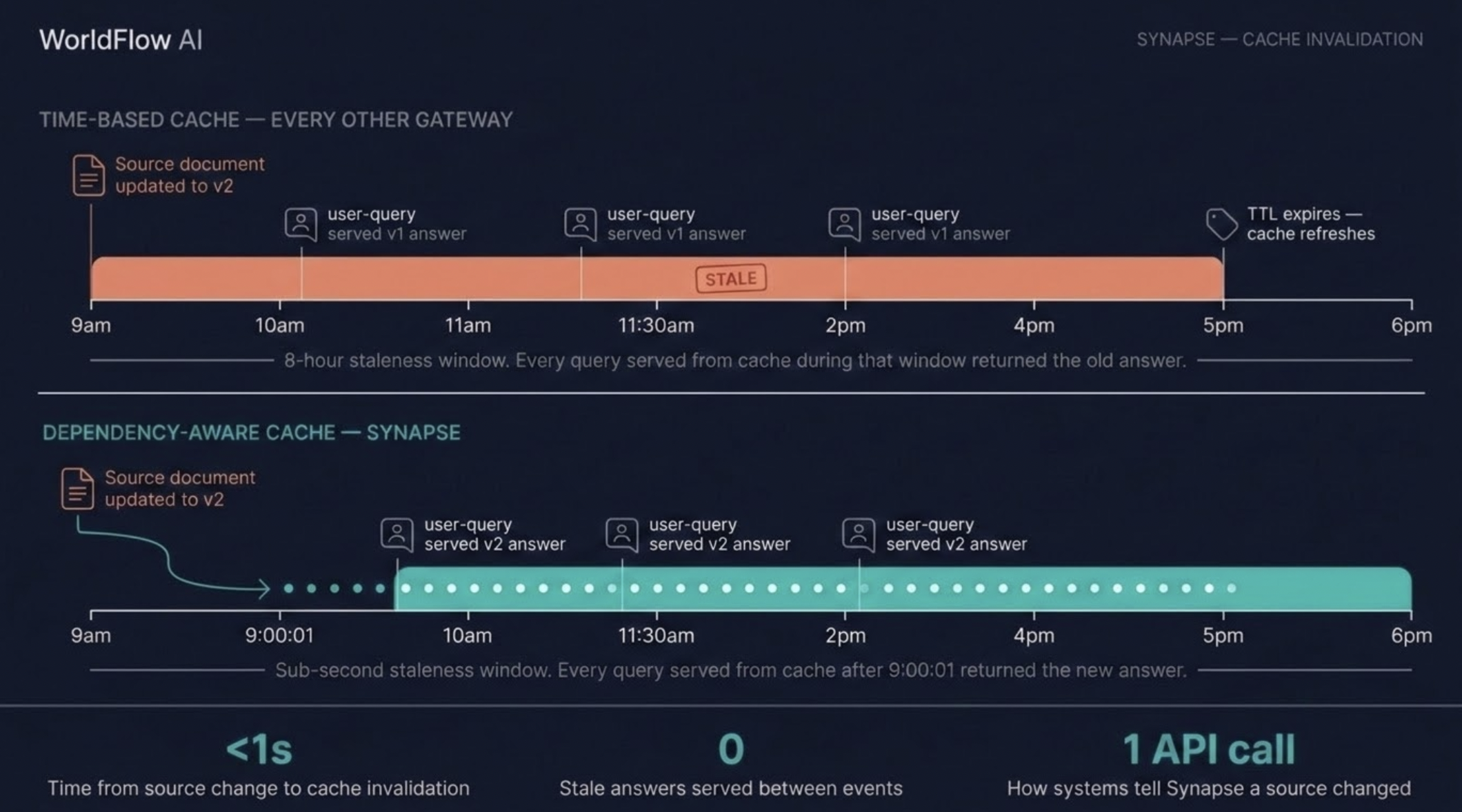
Time is the wrong unit of cache freshness
Every semantic cache shipping today (Portkey, Helicone, Redis Semantic Cache, the major cloud gateway products) invalidates the same way: a TTL counter. Set it to 1 hour, 24 hours, 7 days. Cross your fingers.
The trade-off operators are quietly making is brutal:
- Set the TTL long, and your AI keeps confidently citing stale information for hours after the source changed. Cost looks great. Correctness silently degrades.
- Set the TTL short, and your hit rate collapses. Every "refresh" wipes out the savings you bought the cache to get. Cost grows back. The cache stops earning its keep.
Neither setting is wrong. The unit is wrong.
Time has nothing to do with whether your data has changed. A document that hasn't been touched in three years should keep producing high-confidence cache hits forever. A document edited 90 seconds ago should never produce a cache hit on its old version, no matter what the timer says.
A cache that doesn't know which source documents your answers came from has no way to draw that distinction. It picks a single number and hopes.
Dependency is the right unit
We built Synapse's cache around a different idea: invalidate by what changed, not by when it was last refreshed.
For every answer Synapse caches, it also records the source entities behind that answer: the documents, records, policy IDs, and customer accounts your retrieval layer pulled in to ground the response. Your app already knows these. Your RAG pipeline just retrieved them, so you pass the IDs along with the question. The cached answer and its dependencies are stored together.
When something on your side changes (a document gets updated, a policy gets revised, a customer record gets edited), your system fires one event to Synapse. "Entity X has changed." Within a fraction of a second, every cached answer that depended on Entity X is gone. Every replica in every region. Atomically.
The next user to ask a related question does not get the stale answer. They get a fresh LLM call that incorporates the change. The cache repopulates with the updated truth. Future hits are correct.
What used to be a 24-hour staleness window becomes a millisecond window. The TTL knob still exists, for safety, for the documents you don't have a change signal for. But for everything that does emit a change signal, time stops being the failsafe and starts being the backup.
What it looks like in practice
A few examples from real workloads:
Legal & contract operations. A clause changes. A single API call invalidates every cached AI response that referenced the parent contract. The next time a sales rep asks, the answer reflects the new clause. No more discovery-eve fire drills explaining why the AI cited a paragraph that hasn't existed for a month.
Customer support copilots. A product team updates the refund policy. The support AI's cached "how do I get a refund" answers, across every paraphrase the cache learned over the past month, drop in a single fan-out. The next ten customers get the new policy.
Financial reporting & analytics. A figure in a source spreadsheet gets corrected. Every cached commentary, summary, and Q&A response that drew on it is invalidated together. Auditors stop having to ask whether an AI answer reflects the corrected source.
In each case, the change signal already existed inside your business. The CMS publishes update events. The CRM emits change webhooks. The policy management tool has a "publish new version" action. You were already wiring those signals to other systems. You just couldn't wire them to your cache.
How this changes the math
For most teams, the moment a cache stops forcing a TTL-vs-correctness trade-off, several things shift at once:
| Time-based cache | Synapse (dependency-aware) | |
|---|---|---|
| Staleness window after a source change | Up to TTL (hours to days) | Sub-second |
| TTL setting | Risk-management lever | Safety net for un-instrumented sources |
| Suitability for regulated workloads | Limited; one stale answer can end the rollout | Designed for it |
| Hit rate vs. correctness | Inversely coupled | Decoupled |
| "AI hallucinated" tickets that were actually stale-cache tickets | Common | Rare |
The unlock is not just "fewer wrong answers." It's that the cache stops being a risk you have to manage every quarter and starts being a piece of infrastructure that holds up under the workloads that pay the most.
Why this isn't already table stakes
If the idea is so straightforward, why doesn't every gateway ship it?
Three structural reasons:
Most caches are stateless key-value stores. They index cached answers by a hash of the query and nothing else. Adding dependency-aware invalidation means rebuilding the cache around a bidirectional index: every entity points to every answer that depended on it, and every answer points back to its entities. That is a schema rewrite, not a config knob.
Most gateways don't capture which sources an answer came from. RAG pipelines do, since they retrieve documents before generation. But most gateways sit downstream of the retrieval step and never see the source list. Synapse is positioned in the request flow at exactly the point where source attributions are still visible, so we can record them at cache-write time.
Most gateways have no event surface. To invalidate by dependency, you need an external system to be able to tell you something changed. That's an API endpoint and an event stream as first-class parts of the product. Stitched on later, the result is fragile. Built in from the start, it's reliable.
Each of those is a small architectural decision. Stacked, they produce a kind of cache the rest of the market structurally cannot offer in a patch release.
Where to go from here
Dependency-aware invalidation is on by default in Synapse. If your team is already running a semantic cache and has ever traced an "AI hallucination" back to a stale cached answer, or, worse, ever decided not to roll AI out to a regulated workload because of the correctness risk, we should talk.
The wiring is one event per source change. The unlock is the workloads you've been holding back. Request a demo.