If your company is spending real money on AI inference, the fastest, lowest-risk lever you have is semantic caching. Done well, it can eliminate 40 to 70 percent of redundant LLM calls. The model never even sees most of the requests, and your bill drops accordingly.
This is not a controversial claim. Almost every gateway, every observability vendor, every enterprise AI platform on the market today ships some flavor of semantic cache. The pitch is the same everywhere: same answers, a fraction of the cost.
There is a catch nobody puts in the marketing copy. And it's the reason a lot of teams quietly turn semantic caching off after their first incident.
The hidden trade-off
A semantic cache works by deciding when two questions are "close enough" to share an answer. If a new question is similar enough to one the system has seen before, the cache returns the previous answer and skips the model call. Cheaper, faster, no LLM round-trip.
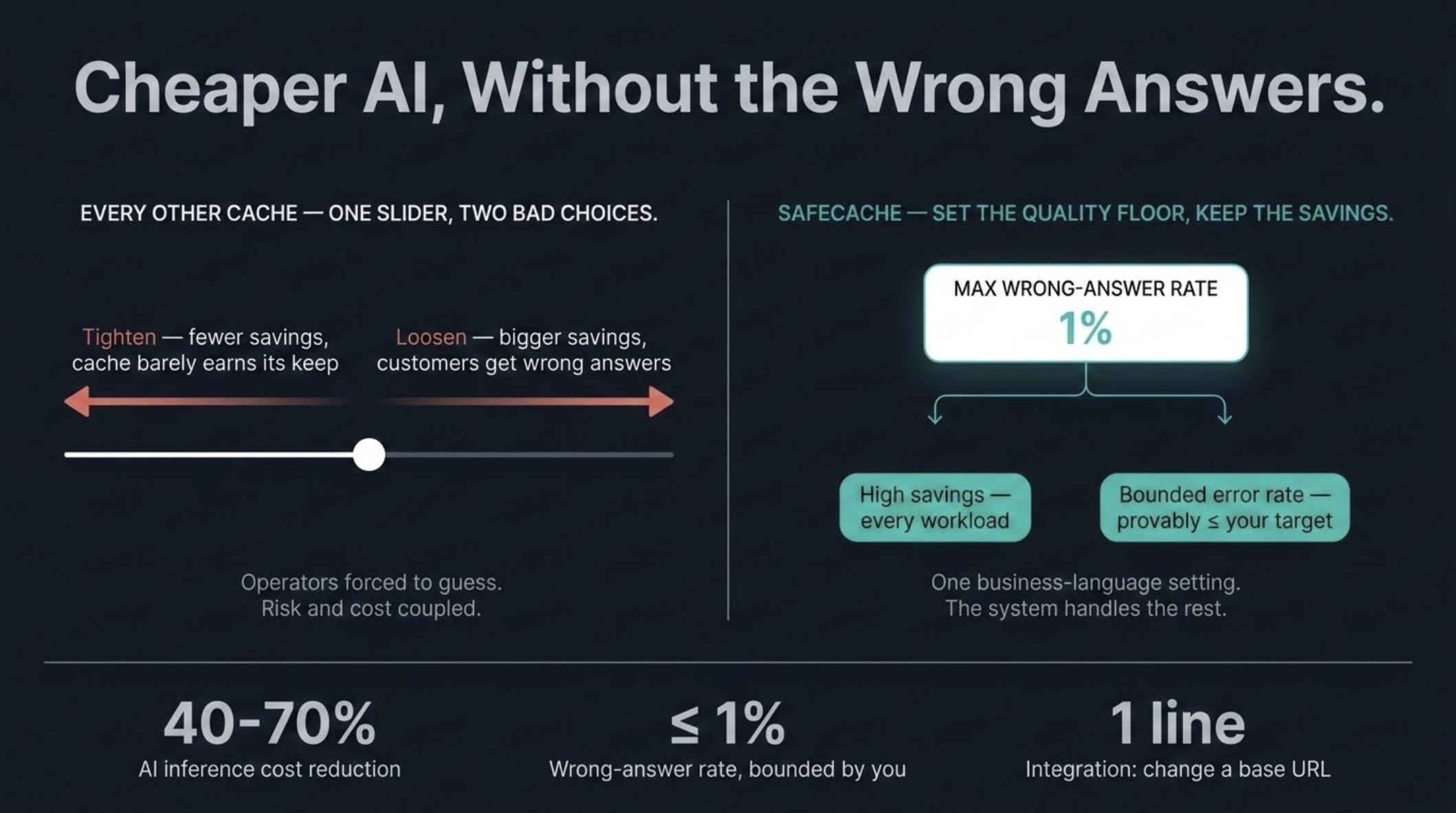
The whole system hinges on that one word: similar. And almost every semantic cache on the market expresses similarity the same way: a single global cutoff, set once, applied to every question in every workload.
That's the catch. A single setting forces you to choose between two bad outcomes:
- Set the cutoff loose, and you save more money, but the cache starts treating questions as identical when they aren't. Your customers receive confidently wrong answers. The cache stops being a cost win and starts being an incident waiting to happen.
- Set the cutoff tight, and you can trust the answers, but the cache barely fires. You're paying for infrastructure that rarely earns its keep.
This is not a knob you can tune your way out of. The right cutoff is different for a billing question than for a code-completion request, different for English than for translated paraphrase, different for short FAQs than for long-context analysis. A single global setting is the wrong shape of control.
For low-stakes consumer apps, that trade-off is annoying but survivable. For enterprises in legal, financial, healthcare, and customer-facing operations, it's the reason semantic caching never gets rolled out company-wide. Or, if it does, the rollout stays confined to a single business unit. The risk of one wrong answer outweighs the savings on a thousand right ones.
A different kind of knob
We built SafeCache, the internal safety mechanism powering Synapse, because the slider was the wrong abstraction.
Instead of asking operators to guess a similarity number that quietly couples cost to risk, SafeCache lets you express the thing you actually care about:
"Save me as much money as possible, but never let the wrong-answer rate exceed x percent."
You set the quality floor. The cache figures out everything else.
Three ideas make that possible:
Per-answer learning. SafeCache treats every cached answer as its own micro-decision. For each one, it learns the relationship between similarity and correctness specific to that answer in your workload. The right cutoff for a billing FAQ is not the right cutoff for a code question, and SafeCache stops pretending it is.
Earned trust. A cached answer that's only been validated a handful of times is treated cautiously. As the system accumulates evidence that an answer is safe to reuse (including signals from a built-in quality judge that runs on borderline cases), it relaxes the cutoff for that specific entry. Older, well-validated entries fire aggressively. New entries earn that aggression over time.
A bounded guarantee. Underneath, SafeCache uses statistical tools that let it commit to an upper bound on how often it can be wrong. You declare a target error rate; SafeCache holds the cache to it. Compliance, security, and platform teams get something they've never been able to get from a semantic cache before: a defensible answer to "how do you guarantee this won't hallucinate at scale?"
There's real machinery underneath those three ideas. We'll go deeper in a follow-up post for the engineering audience. For buyers, the surface is what matters: one knob, the right knob, expressed in business units instead of mathematical ones.
What this changes for your team
A few things shift the moment a cache stops forcing the cost-versus-correctness trade-off.
Caching becomes deployable to the workloads where it matters most. Legal review, claims handling, support agents, internal copilots. The workloads with the largest spend are also the ones with the lowest tolerance for wrong answers. A bounded-error cache is the only kind that can responsibly run there.
Operators stop guessing. Instead of telling a platform team to "tune the similarity threshold," product owners tell them "we accept up to 1 percent wrong answers, optimize savings against that." That's a conversation a CFO can have. A similarity slider is not.
Cost becomes predictable. Because SafeCache holds a quality floor regardless of workload, you stop paying the hidden tax of post-incident rollbacks, manual threshold re-tuning, and "we turned the cache off in this region after that bad day." The savings compound instead of regressing.
The illustrative shape of the gain, on a typical enterprise workload:
| Standard semantic cache | SafeCache | |
|---|---|---|
| Wrong-answer rate | 3–5% | Bounded at your declared target (e.g. 1%) |
| Cache hit rate | High, until incident forces rollback | High and stable across workloads |
| Operator burden | Continuous threshold tuning per workload | Set quality floor once |
| Suitability for regulated workloads | Limited | Designed for it |
Why it's not table-stakes yet
Per-answer adaptive thresholds with a formal error bound aren't a feature flag the rest of the market can flip on next quarter. They depend on a quality-evaluation layer running continuously inside the cache, on an architecture that holds online state per cached answer, and on operators having a way to express quality targets as first-class settings rather than hidden tuning parameters. Stitching those together is a years-long architecture decision, not a sprint.
That's why SafeCache exists in our platform and not, today, in anyone else's.
The bottom line
Semantic caching is still the highest-ROI lever in enterprise AI. SafeCache is what makes that lever safe to pull at the workloads where the savings are largest and the stakes are highest.
If your team is spending meaningfully on LLM inference and has either avoided semantic caching because of correctness risk, or rolled one out and felt the trade-off bite, we should talk. The integration is one base URL change. The savings show up in the first week. And for the first time, you don't have to choose between them and the trust of the answers your customers are getting.